|
Testing Foundations
|
July, 1995
You may click on the[c] links at any time to return to the Contents.
Doing testing means doing three things: designing tests, implementing the tests you've designed, and evaluating those tests. Test design is essential to effectiveness. Test implementation is essential to efficiency. Test evaluation improves effectiveness.
More people are weak at design than at implementation, though that's not always obvious (because implementation problems are more immediate and pressing). I tend to concentrate on design.
Before test design, there is test planning, preferably guided by risk analysis. I'm not going to talk about that, or about other aspects of managing testing.
I believe there are two useful approaches to test design: testing based on plausible faults and testing based on plausible usage. In this first part, I'll discuss the first. In Part 2, I'll discuss the second.
Warning: many people think of testing, at least at the code level, as being about exercising all the lines of code or some set of paths through the code. I don't believe path-based testing is particularly useful. That is, the types of testing I'll discuss do what typical path-based techniques do, and more besides. So I ignore paths. If you want to see how path-based testing is affected by OO, this is not the document for you.
This type of testing can be based on the specification (user's manuals, etc.) or the code. It works best when based on both. I'll concentrate on the code. (Whatever else may be missing, you've always got the code.)
I'll start with an example. Programmers make off-by-one errors. So when testing a SQRT function that returns errors for negative numbers, we know to try the boundaries: a negative number close to zero, and zero itself. "Zero itself" checks whether the programmer made a mistake like:
instead of the correct:
As another example, suppose you have a boolean expression:
Multicondition testing and related techniques probe for certain plausible faults in that expression, such as:
For each plausible fault, the technique gives you an input that will make the the given, incorrect, expression evaluate wrong. In the expression above, (a=0, b=0, c=0) will make the expression as given evaluate false. If the "&&" should have been a "||", the code has done the wrong thing; it's now taking the wrong path.
Of course, the effectiveness of these techniques depends on their definitions of "plausible fault". If the real faults are all ones that they consider "implausible", these techniques are no better than any random technique. In practice, they work pretty well.
As a side benefit, such techniques will force every line of code to be executed, discovering the large class of faults that invariably fail. Example:
fprintf("Hello, %s!\n"); // two missing arguments
Integration testing looks for plausible faults in function calls. Here are some examples of faults:
write(fid, buffer, amount); The code does not check for error returns from write().
if (-1 == write(fid, buffer, amount)) error_out(); The code assumes a non-negative return means every byte has
been written. That's not necessarily the case. It may be that
only part of the buffer was written (in which case write()
returns a number less than "amount".)
ptr = strchr(s, '/'); The programmer should have used "strrchr". As written, the code searches for the first slash when it should search for the last.
if (strncmp(s1, s2, strlen(s1)))... The programmer should have used "strlen(s2)".
The above plausible faults are of three types: unexpected
result, wrong function used, incorrect invocation. What I call
integration test design searches for the first and third types. (I
won't talk about the second here.) The search depends on an
examination of the behaviors of the called function. In the case
of a call to write(), that search would lead to
these test requirements:
In the case of any call to strncmp(string1, string2, length), it leads to these test requirements:
Integration testing applies to variables as well as to functions. The "behaviors" of the variable are the different kinds of values it can have. You test whether the using code handles each kind of value. (Further discussion omitted.)
IMPORTANT POINT: Integration testing is about finding faults in the calling code, not the called code. The function call is used as a clue, a way to find test requirements that exercise the calling code.
There are several ways OO programming could make a difference:
I'll discuss the last issue first.
When you stare at a chunk of code in an OO program, a few novelties strike you:
But what's the essential difference? Before OO, when you looked at
x = foo(y);
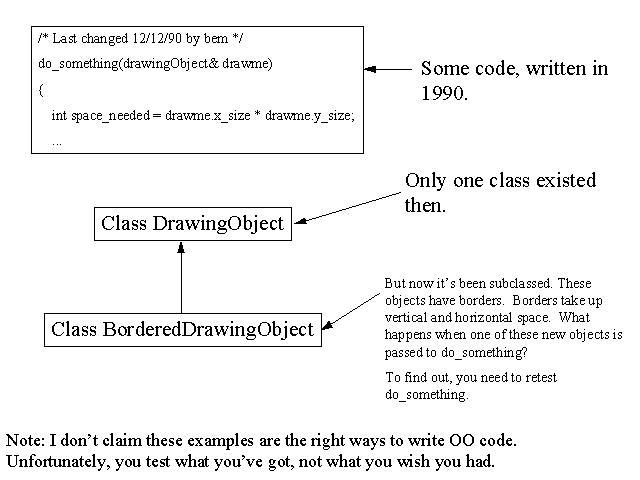
you had to think about the behaviors of a single function. Now you may have to think about the behaviors of base::foo(), of derived::foo(), and so on. For a single call, you need to explore (or at least think about) the union of all distinct behaviors. (This is easier if you follow good OO design practices, which tend to limit the differences in behavior between base and derived classes.)
The testing approach is essentially the same. The difference is one of bookkeeping. (I don't mean to minimize the importance of bookkeeping. As anyone who's stuggled through the OO chapters in my book knows, the bookkeeping for a sloppy OO design is overwhelming.)
The problem of testing function calls in OO is the same as testing code that takes a function as a parameter and then invokes it. Inheritance is a convenient way of producing polymorphic functions. At the call site, what matters is not the inheritance, but the polymorphism. Inheritance does make the search for test requirements more straightforward.
As with functions, the process of testing variable uses doesn't essentially change, but you have to look in more places to decide what needs testing.
Has the plausibility of faults changed? Are some types of fault now more plausible, some less plausible?
OO functions are generally smaller. That means there are more opportunities for integration faults. They become more likely, more plausible. With non-OO programs, people often get away with not designing tests to probe for integration faults. That's less likely to work with OO programs.
It may be that people can now get away with not designing tests to probe for boundary faults, boolean expression faults, and so on. I don't know, but I doubt it.
Suppose you have this situation:
Derived::redefined has to be tested afresh: it's new code. Does derived::inherited() have to be retested? If it calls redefined(), and redefined's behavior changed, derived::inherited() may mishandle the new behavior. So it needs new tests even though the code hasn't changed.
Note that derived::inherited() may not have to be completely tested. If there's code in inherited() that does not depend on redefined() that does not call it, nor call any code that indirectly calls it that code need not be retested in the derived class.
Here is an example:
Base::redefined() and derived::redefined() are two different functions with different specifications and implementations. They would each have a set of test requirements derived from the specification and implementation. Those test requirements probe for plausible faults: integration faults, condition faults, boundary faults, etc.
But the functions are likely to be similar. Their sets of test requirements will overlap. The better the OO design, the greater the overlap. You only need to write new tests for those derived::redefined requirements that are not satisfied by the base::redefined tests.
Notes:
Here is an example:
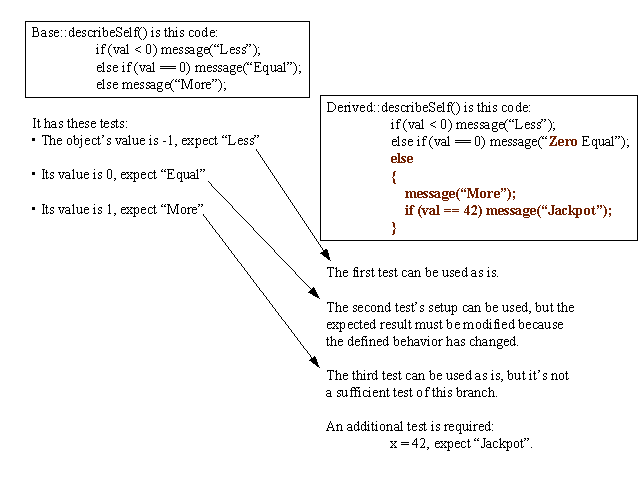
There's a problem here, though. The simpler a test, the more likely it is to be reusable in subclasses. But simple tests tend to find only the faults you specifically target; complex tests are better at finding both those faults and also stumbling across other faults by sheer dumb luck. There's a tradeoff here, one of many between simple and complex tests.
Suppose you add the "derived" class. There may be a whole lot of code that looks like
mumble = x->redefined();
...
Before, that code could only be tested against the behaviors of base::redefined, the only version of redefined() that existed. Now you (potentially) have to look at all code that uses redefined(), decide if it could be passed a "derived", then test it with test requirements that describe the difference between the behaviors of base::redefined() and derived::redefined().
Here's an example: