Three proposed workshops in Europe
I’ll be in Europe definitely between 9 April (Bristol) and 20 April (Kiev) and likely either before or after those dates. I have some ideas for workshops that we might have while I’m there, provided we can scare up someone to do the local arrangements (venue, mainly). I can work on finding participants, though help would be greatly appreciated.
Here are the ideas:
“Shell and Guts” combinations of object-oriented and functional programming
There’s been much talk about a strategy of having functional cores, nuggets, or guts embedded within an object-oriented shell. Here’s a picture from my recent book:
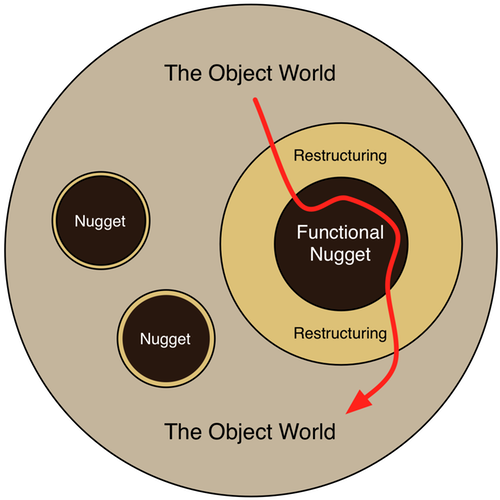
At SCNA, Gary Bernhardt described a different-but-similar approach. (Very neat - incorporating actor-ish communication between shells.)
This workshop would be about exploring the practicalities of such an approach. (Credit to Angela Harms, who proposed a workshop like this to me and Mike Feathers.)
Next steps in unit testing tools
This would bring together tool implementors, power users, and iconoclastic outsiders to make and critique proposals for moving beyond the state-of-the-practice of unit testing tools. Bold proposals might include: use QuickCheck-style generative/random-ish testing instead of or in addition to conventional TDD, or claiming that the next step in TDD is incorporating or replacing the sort of bottom-up tinkering in the interpreter that’s common in (for example) the Lisp tradition.
Community building for language and tool implementors
Although I released my first open-source tool in 1992, I’ve always been lousy at building communities around those tools. Other people have succeeded. This workshop would be a collection of people who’ve succeeded and who’ve failed, sharing and refining tips, tricks, viewpoints, and styles.
Format
Of the various meeting formats I’ve experienced, one of the most productive has been the LAWST format that I learned from Cem Kaner and Brian Lawrence. Some of the LAWST workshops produced concise, group-approved lists of statements that had substantial influence going forward. These three workshops seem like the kind that should produce such statements.
The LAWST format works best if it has a facilitator who has no stake in the topic at hand. (Such facilitators might well follow the style of How to Make Meetings Work or Facilitator’s Guide to Participatory Decision-Making.) I’d hope the local arrangements person could help find such.
If you’re interested in making one of these workshops happen, please contact me.