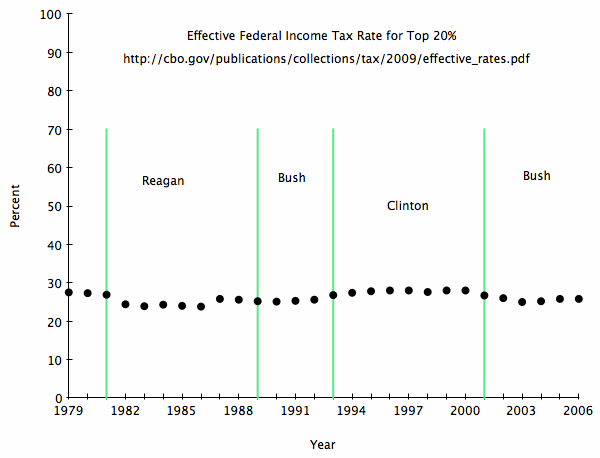
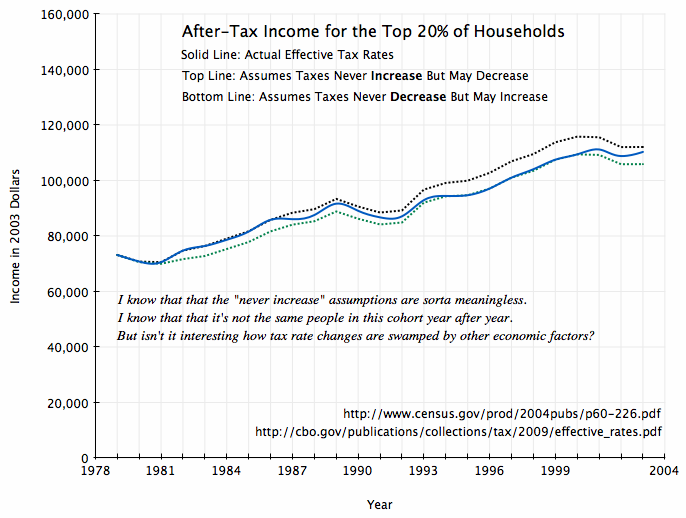
Part 1
Part 3
I ended Part 1 saying that my next step would be to implement a function that counts the number of living neighbors a cell has. Given that we’re already pretending (through stubbing) that a living? function exists, living-neighbor-count is pretty trivial if we also pretend we’ve got a neighbors function:
Following my “mapping, like accessors, is too simple to test” guideline, I almost didn’t write a test. But what the heck:
Once the test passes, we need to write neighbors. To implement it, we’re going to have to take cells apart (to get x and y coordinates) and put them back together (to create neighbors). So I don’t see any point to using stubs and dummy variables like ...cell... in this test:
Boldly, I will here use one test to define both cell-at and neighbors (as well as the test helper have-coordinates that checks a list of cells against a list of coordinates).
(If I were more sensitive to that small voice in my head that warns I’m going astray, I would have heard something around now, but I ignored it. So we will too.)
Enter the REPL
My thought about how to implement neighbors has three steps, so I’ll try them out in the REPL. First, I’ll make (x,y) pairs to add and subtract from the original cell’s coordinates:
That’s good, except (0, 0) shouldn’t be in there. (A cell can’t be its own neighbor.) So I need to delete that:
(remove #{[0 0]} product) is a Clojure idiom. remove returns its second (sequence) argument, omitting any element that the first argument (a function) returns truthy for. #{x} is the set containing x. In Clojure, sets act as functions that return something truthy iff their single argument is in the set. That is:
Finally, I need a function that shifts a cell by an offset. For the REPL, I’ll pretend the cell is just an [x y] vector. (We have yet to define what it really is.)
I can build neighbors from what I’ve tried out. To make the test pass, I’ll continue to use vectors for cells, hiding them behind a simple functional interface of cell-at, x, and y.
The concrete representation of the cell — and disaster
Here are the functions as yet undefined:
There’s no more escaping it. I’m going to have to decide what kind of thing border produces. That thing has to be a sequence for tick to map over:
border's result is also stored in world where living? will use it to decide whether a given cell is alive or dead.
My first thought was that I could use the set idiom I used above—the bordered world could just be the set of all living coordinates. Sneakily, any location not in the set would represent a dead cell. That would be great for implementing living?, but it wouldn’t work for tick, which has to process not only living cells, but also the dead cells that make up the border.
So my fallback was for border to produce a map, something like this:
Maps are sequences, so you can map over them. But I don’t think I’ve ever actually tried it. What happens?…
OH GREAT. If I go down this route, we’ll have three different ways of representing cells:
-
as the original location in inputs like
*vertical-blinker*: [0 1]
-
as part of a living/dead map:
{... [0 1] :dead ...}
-
as a living/dead vector:
[ [0 1] :dead ]
That’s intolerable. And yes, I bet at least half of my two readers thought I was mistaken not to think about data structures at the very beginning. However, my strategy with Clojure TDD has been to put off thinking about data structure as long as I can, and I’ve been surprised and pleased by how often I ended up with simpler data than it seemed I would. I’ve found that, given the use of globally-available immutable “background” data, much of what might have been explicit data structure–vectors of maps of vectors of…–ends up in the implicit structure of the computation. More about that, though, will have to wait for another post.
A recovery plan
The problem is here:
When I wrote that, I remember that the still small voice of conscience objected to the way I was both stashing the bordered-world away as background and simultaneously picking it apart with map. That just felt weird, but I argued myself into thinking it was harmless. It was not.
Really, since my whole program takes input [x y] pairs (such as *vertical-blinker*) and turns them into a different set of [x y] pairs, most of my work ought to be done with those pairs. I should be thinking about locations of cells, not cells themselves. In that way of thinking, border shouldn’t produce “cells”. It should take locations of living cells and produce locations that point to both living cells and adjacent dead cells.
Further, I shouldn’t repeat those locations in a world function. Instead, I need something that can answer questions about cells, given their locations. It should be a… (I’m bad with names)… an oracle about cells. I first imagined this:
using-cell-oracles-from should produce any wise and oracular functions we need. So far, that’s just living?.
I realized something more. Locations are flowing into the pipeline, locations are flowing out, and in this version, locations won’t be transformed into cells anywhere within the pipeline. That makes unborder, which was originally supposed to convert a mixture of living and dead cells into only living locations, seem kind of stupid. If tick produces only living locations, unborder can go away. (The name unborder always bugged me, because it didn’t really describe what the function would have to do. Once again, I should have paid attention.)
That leads to this top-level function:
That wasn’t so bad…
As it turns out, changing my mind about such a fundamental decision was easy.
What did I have to do to the code? I had to write using-cell-oracles-from. Here’s a test.
I won’t show the code that passes this test—it’s a somewhat grotty macro (but a simple transformation of the earlier against-background). You can see it in the complete source for this post.
I did a quick global-replace of “cell” with “location” and tweaked a couple of the resulting names. Although both you and I know that locations are just pairs, I retained the functions make-location (formerly cell-at), x, and y to keep the code insulated from the potential of another change of mind.
I had to convert the successor function to dead-in-next-generation?. That was pretty simple. I had to change two lines in the test. Here’s one:
To make that test pass, I had to rewrite successor. It used to be this:
Now it’s this:
That was just a matter of inverting the logic and deleting killed and vivified. (Before I ever got around to writing them!)
The ease of this change makes me happy. Even though I blundered at the very beginning of my design, the way stub-heavy TDD lets me defer decisions—and forces me to encapsulate them so that I have something to stub—made the blunder a not-catastrophe. I wish I could say that I blundered deliberately to demonstrate that property of this style of TDD, but that would be a lie.
Enough for today
Only one function remains: add-border-to. That’ll be pretty easy, but this post is already too long. The next one will finish up the implementation and add whatever grand summary I can come up with.