
Two phase release planning
A twitter conversation between Zee Spencer and Ron Jeffries makes me think I’ve never written down my two-phase approach to release planning.
Phase 1: Someone wants something. They have a problem to be solved by a software system. There are probably a few key features that are needed, perhaps buried in a mass of requirements that pretend to more authority than they’ll turn out to have. If the key features aren’t delivered, the system isn’t worth having. (Or the new release of an existing system isn’t worth having - it doesn’t matter.)
The person who wants the system (or wants to sell it) might have a release date in mind. It might be based on real constraints, like the beginning of a school year or the Christmas sales season. Or it might be arbitrary. Doesn’t matter to me.
At this point, the development team’s job is to answer the question: can this team produce a respectable implementation of that system by that date?
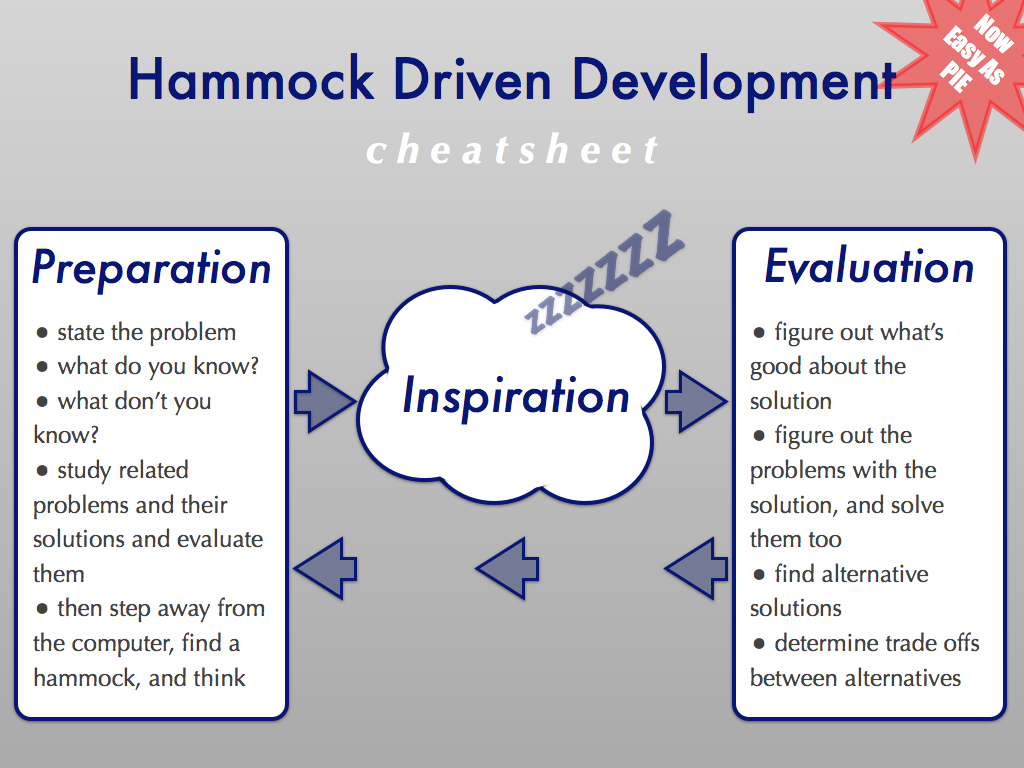
“Respectable” is a somewhat tricky idea. One conceptually easy part of it is “provides the key features”. Another is, embarrassingly, fuzzier: more about whether something can be provided that feels like a “whole” rather than a collection of parts. This is the kind of thing that Jeff Patton’s story mapping is about. It also includes Jeff’s idea of the distinction between incremental development (where you develop by bolting on features one at a time) and iterative development (where you get something complete-for-some-real-purpose done quickly but crudely, then add flesh to the walking skeleton.)
The answer to the “can it be done by that date?” question is going to be something of a leap of faith. The estimate that “we can do that by then” isn’t going to be as reliable as, say, the use of yesterday’s weather in iteration planning.
One way to get a better answer is to just go ahead and start the project. As Cem Kaner has said, you know less about the project right now than you ever will again. Spend a month building the product, then ask: can it be built by the desired date? You’ll get a much better answer. [Note: I’d favor really starting to build the project, just as if you’d made a two-year commitment, rather than doing some pilot study. I’d be suspicious that a pilot study would ignore a lot of the grinding details that take up a lot of project time.] The risk here, though, is that an answer of “well, it turns out we won’t be able to do it” will be unacceptable.
(Whether estimating at the beginning or after a month, I’d personally err on the conservative side because my experience is (1) the development team is more likely to be optimistic than pessimistic, and (2) I favor pleasant surprises - “We can do more! Or release sooner!” - over unpleasant ones.)
Phase 2: At this point, there’s a commitment: a respectable product will be released on a particular date. Now those paying for the product have to accept a brute fact: they will not know, until close to that date, just what that product will look like (its feature list). What they do know is that it will be the best product this development team can produce by that date. It’ll be the best product because the team commits to being flexible enough to put features into the product in any order. Therefore, the most valuable features can go in first, then the less valuable ones, then…
So, in this phase, you can stop worrying about anything but the near horizon. For much of the project, all that’s required is occasional stock-taking. (”Do we still think we’ll have a respectable product by the release date?”) Toward the end, there might be some need to predict more precisely than “best possible, given this team and that date”. Not everything that needs to be done before release might be as changeable as the code. (It’s harder to un-train a salesperson than to turn off the code for a feature that won’t be done in time.) But you’ll be in a good position to make good predictions by then.
——–
My success selling this approach has been mixed. People really like the feeling of certainty, even if it’s based on nothing more than a grand collective pretending.
{kind=link}