
Exploration Through Example
Example-driven development, Agile testing, context-driven testing, Agile programming, Ruby, and other things of interest to Brian Marick
| 191.8 | ⇒ | 167.2 | ⇒ | 186.2 | 183.6 | 184.0 | 183.2 | 184.6 |
Exploration Through ExampleExample-driven development, Agile testing, context-driven testing, Agile programming, Ruby, and other things of interest to Brian Marick
|
|
Sun, 28 Jan 2007The simplest thing you could possibly decide I've been working some more on my sample model-view-presenter app, mainly finishing up the Fit tests in preparation to changing gears and "repurposing" it as an Ajax app. I've been adding new UI behaviors bit by bit. As I've been doing so, the app's complexity has been bugging me. As you may recall, any change to UI can affect as many as 10 classes (three model/view/presenter classes for each of three windows, plus a coordinator class that keeps MVP triads in sync). This somehow doesn't seem to square with Beck's advice to minimize classes and methods, nor with Do The Simplest Thing That Could Possibly Work. However, I realized that a big part of test-driven design is to make each decision small by deferring other parts of the problem until later. MVP is like that. You begin with a test that describes what one user gesture does to everything visible on the screen. That gesture drives a pretty obvious change to the View, which drives a pretty obvious change to the Presenter, which drives a pretty obvious change to the Model (what I've been calling the Application object). That drives a pretty obvious change to the Coordinator, which... It's all fairly rote, and there are nice milestones along the way as each window comes into conformance with the business-facing test.
What remains to be seen is how all this will handle change. That's the reason I'm going to switch to a radically different UI. Instead of looking like a multi-document/multi-window app, I'm going to model it after the Synk synchronization/backup program. (Click through the picture to see more.)
## Posted at 09:21 in category /coding
[permalink]
[top]
Tue, 09 Jan 2007The end of my one-typo coding rule (updated) Long ago, two bugs made a profound impression on me. One bug was in a Unix kernel function that did something-or-other with inodes (integer indexes into the file system). The function header looked like this:
The original programmer had somewhere used an
The other bug was because a programmer used From these experiences I devised a rule: Don't create two identifiers one typo apart.
That rule made me an outcast. Other programmers laughed at me because I
didn't use However, today I'm working in Java with Intellij IDEA. Just now, I realized one constant needed to be two:
When using them, I don't type those full names. Instead, I type Many more identifiers are now one typo apart. Rats. 1 They also laughed at me for writing C conditionals like this:
instead of
(For the non-C programmers among you, the second form is one typo
away from That was back when I was working on Common Lisp for the Gould PowerNode, and one C programmer looking at my code said, "Is that some kind of weird Lisp thing?" I don't think I ever convinced anyone to do it the safer but awkward way. That was not the first time I noticed that aesthetics trumps cost-benefit analysis. (In case you're wondering, I'm not changing my two constant names. I'm thinking that it'll be too hard to come up with memorable, meaningful names that are not a typo apart, so I'm abandoning my rule. Maybe a bad idea, but I don't claim to be any less swayed by aesthetics and personal preference than anyone else is.)
UPDATE: I just spent ten minutes tracking down a problem caused by
using
## Posted at 09:03 in category /coding
[permalink]
[top]
Tue, 18 Jul 2006A while back, I sat in while Ralph Johnson gave a dry run of his ECOOP keynote. Part of it was about refactoring: behavior-preserving transformations. The call was for research on behavior-changing transformation that are like refactorings: well-understood, carefully applied, controlled. Ralph mentioned that persistent question: what does "behavior-preserving" mean? A refactoring will change memory consumption, probably have a detectable effect on speed, etc. My reaction to that, as usual, was that a refactoring preserves behavior you care about. Then I thought, well, you should have a test for behavior you care about. ("If it's not tested, it doesn't work.") That, then, is my new definition of refactoring: A refactoring is a test-preserving transformation. If you care about performance, a refactoring shouldn't make your performance tests fail.
## Posted at 21:30 in category /coding
[permalink]
[top]
Thu, 15 Jun 2006I'm practicing for a set of five demos I'm doing next week. In each, I'll work through a story all the way from the instant the product director first talks about it, through TDDing the code into existence, and into a bit of exploratory testing of the results. Something interesting happened just now. Step one of the coding was to add some business logic to make a column in a Fit table pass. In step two, I worked on two wireframe tests that describe how the sidebar changes. These tests mock out the application layer that sits between the presentation layer and the business logic. What remained was to change the real application layer so that it uses the new business logic. That, I said (imagining my talk), is so simple that I'm not going to write a unit test for it. Even if I do mess it up (I claimed), I have end-to-end tests that will exercise the app from the servlets down to the database, so those would catch any problem. You can guess the results. I made the change and ran the whole suite. It passed. Then I started up the app to see if it really worked, and it didn't. The problem is in this teensy bit of untested code:
The problem is that I have an extra From this, we can draw two lessons:
I'm still not inclined to write a unit test. This is the neatest thing to happen to me today. But nothing like it better happen in the real demo.
## Posted at 20:09 in category /coding
[permalink]
[top]
Thu, 08 Jun 2006Three ages of programming (update) Update to the previous article from Andy Schneider. The term "scrapheap programming" may date back to Noble & Biddle's OOPSLA '02 Postmodern Programming Extravaganza. (The Biddle link is an old one, but the newer one I found had less on it.) Pete Windle was the coauthor on the paper of Andy's I cited. Sorry, Pete.
## Posted at 11:32 in category /coding
[permalink]
[top]
Tue, 06 Jun 2006Let's pretend there have been three ages of programming: the Age of the Library, the age of the Framework, and the Age of the Scrapheap. They correspond to three ages of documentation: the Age of Javadoc, the Age of Javadoc (plus the occasional tutorial), and the Age of Ant. The first substantial program I ever wrote was a reimplementation of Plato Notes (think USENET news) for the TOPS-10 operating system. To do that, I only had to learn two things: Hedrick's Souped Up Pascal and the operating system's API. I don't remember the documentation for Hedrick's Pascal - probably I mainly used Jensen and Wirth. If you've read most any book defining a programming language, you'd recognize the style. The operating system was documented with a long list of function calls and what they do. Anyone who's seen Javadoc would find it unsurprising—and vice-versa. This style of documentation says nothing in particular about how to organize your program or how the pieces should fit together. The next Age provides more structure in the form of frameworks. JUnit is a familiar example: you get a bunch of classes that work together but leave some unfilled blanks, and you construct at least a part of your application by filling in those blanks. A framework will usually come with Javadoc (or the equivalent for the framework's language). There's likely to be some sort of tutorial cookbook that shows you how to use it, plus—if you're lucky—a mailing list for users. The third age is the age of Scrapheap Programming (named after a workshop run by Ivan Moore and Nat Price at OOPSLA 2005). In this style, you weave together whole programs and large chunks of whole programs to solve a problem. (See Nat's notes.) The scraps have a sideways influence on structure: unlike frameworks, they are not intended to shape the program that uses them. But they have a larger influence on the structure than the APIs do. APIs still allow the illusion of top-down programming, where you match the solution to the problem and don't worry about the API until you get close to the point where you use it. In Scrapheap programming, it seems you rummage through the scrapheap looking for things that might fit and structure the solution around what you find. What of documentation? Programming has always benefited from a packrat memory. One of the first things I did in my first Real Job was to read all the Unix manpages, sections 1-8, and just last year I surprised myself by remembering something I'd probably learned in 1981 and never used since. But I'm not so good at learning by using, which seems more important in scrapheap programming than in the previous ages. There are two parts to that learning. You need to somehow use the world to direct your attention to those tools that will be useful someday: Greasemonkey, Cygwin, Prototype, and the like. Next, you have to play with them efficiently so that you quickly grasp their potential and their drawbacks. Perhaps what's needed today is not only a Programming Language of the Year club, but a Dump Picking of the Month club. I'm fighting the temptation to start one right now. There's a variant of dump picking that plays to my strengths. Once last month, I was faced with a problem and I said "Wait - I remember reading that RubyGems does this. I wonder how?" A short search of the source later, and I found some code to copy into my program. Last week I used something Rake does to guide me to a solution to a different problem. Which raises another issue of skill. I'm halfway good at understanding Ruby code, even at figuring out why a Ruby app isn't working. As I've discovered when looking for a Java app to demonstrate TDD, I'm much worse at dealing with Java apps. When I download one, type 'ant test', and see about 10% of the tests fail (when none should), I don't know the first obvious thing a Java expert would do. I liken this to patterns. There was a time when the idea of Composite was something you had to figure out instead of just use. There was a time when Null Object was an Aha! idea. As happened with small-scale program design, the tricks of the trade of learning code need to be (1) pulled out of tacit knowledge, (2) written down, (3) learned how to be taught, and (4) turned into a card game. I don't know who's working on that. A couple of sources come to mind: Software Archaeology, by Andy Hunt and Dave Thomas, and Software Archaeology, by Andy Schneider.
## Posted at 21:34 in category /coding
[permalink]
[top]
Wed, 15 Mar 2006Why is it that I so stubbornly believe that code can get more and more malleable over time? — Two early experiences, I think, that left a deep imprint on my soul. I've earlier told the story of Gould Common Lisp. The short version is that, over a period of one or two years, I wrote thousands of lines of debugging support code for the virtual machine. Most of it was to help me with an immediate task. For example, because we were not very skilled, a part of implementing each bytecode was to snapshot all of virtual memory,* run the bytecode in a unit test, snapshot all of virtual memory again, diff the snapshots, and check that the bytecode changed only what it should have. The program ended up immensely chatty (to those who knew how to loosen its tongue). There are two questions any parent with more than one child has asked any number of times: "all right, who did it?" and "what on earth was going through your mind to make you think that was a good idea?" The Lisp VM was much better at answering those questions than any human child. I was only three or so years out of college, still young and impressionable. Because that program had been a pleasure to work with, I came to think that of course that was the way things ought to be.
Later, I worked on a version of the Unix kernel, one that Dave
Fields called
the Winchester
Mystery Kernel, so I became well aware that not all programs
were that way. But at the time, I was also a maintainer of GNU Emacs
for
the Gould
PowerNode. With each major release of Emacs, I made whatever
changes were required to make it run on the PowerNode, then I fed
those changes back to Stallman. Part of what I worked on
was That experience also made an impression on me, and probably accounts for a tic of mine, which is to hope that each change will give me an excuse to learn something new about the way the program ought to be. I've been lucky in the experiences I've had. A big part of my luck was being left alone. No one really cared that much about the Lisp project, so no one really noticed that I was writing a lot of code that satisfied no user requirement. GNU Emacs was something I did on my own time, not as part of my Professional Responsibilities, so no one really noticed that Stallman pushed harder for good code than those people who were paid to push hard for good code. I'm not sure whether people on the Agile projects of today have it better or worse. On the one hand, ideas like the above are no longer so unusual, so it's easier to find yourself in situations where you're allowed to indulge them. On the other hand, people's actions are much more visible, and they tend to be much more dedicated to meeting deadlines—deadlines that are always looming. I'm wondering these days whether I'm disenchanted with one-week iterations. I believe that the really experienced team can envision a better structure and move toward it in small, safe steps that add not much time to most every story. I'm not good enough to do that. I need time floundering around. To get things right, I need to be unafraid of taking markedly more time on a story than is needed to get it done with well-tested code that's not all that far from what I wish it were (but makes the effort to get there one story bigger and so one story less likely to be spent). It's tough to be unafraid when you're never more than four days from a deadline. So I think I see teams that are self-inhibiting. When I work with programmers (more so than with testers), I find it difficult to calibrate how much to push. My usual instinct is to come on all enthusiastic and say, "Hey, why don't we merge these six classes into one, or maybe two, because they're so closely related, then see what forces—if any—push new classes out?" But then I realize (a) I'm a pretty rusty programmer, (b) I know their system barely at all, (c) they'll have to clean up any mess we make, not me, and (d) there's an iteration deadline a few days away and a release deadline not too far beyond that. So I don't want to push too hard. But if I don't, someone's paying me an awful lot of money to join the team for a week as a rusty programmer who knows their system barely at all. It ought to be easier to focus just on testing, but the same thing crops up. There, the usual pattern goes like this: I like to write business-facing tests that use fairly abstract language (nowadays usually implemented in the same language as the system under test). My usual motto is that I want to see few words in the test that aren't directly relevant to its purpose. Quite often, that makes the test a mismatch for the current structure of the system. It's a lot of work to write the utility routines (fixtures) that map from business-speak to implementation-speak. Now, it's an article of faith with me that one or both of two things will probably happen. Either we'll discover that the fixture code is usefully pushed down into the application, or a rejiggering of the application to make the fixtures more straightforward will make for a better design. But..., (a) if I'm wrong, someone else will have to clean up the mess (or, worse, decide to keep those tests around even though they turned out to be a bad idea), and (b) this is going to be a lot of work for a feature that could be done more easily, and (c) those deadlines are looming. I manage to muddle through, buoyed—as I think many Agile consultants are—by memories of those times when things just clicked. * The PowerNode only had 32M of virtual (not physical) memory, so snapshotting it was not so big a deal.
## Posted at 18:40 in category /coding
[permalink]
[top]
Sun, 30 Oct 2005A thought on mocking filesystems (Sorry about the earlier version of this. I wrote some notes locally and then accidentally synchronized with testing.com.) Sometimes people mock (or even just stub) some huge component like a filesystem. By doing that, you can test code that uses the filesystem but (1) have the tests run much much faster, (2) not have to worry about cleaning up because the fake filesystem will disappear when the test exits, (3) not have to worry about conflicting with other tests running at the same time, and (4) have more control over the filesystem's behavior and more visibility into its state. I was listening to someone talk about doing that when I realized that any component like a filesystem has an API that's adequate for a huge number of programs but just right for none of them. So it seems to me that a project ought to write to the interface they wish they had (typically narrower than the real interface). They can use mocks that ape their interface, not the giant one. There will be adapters between their just-right interface and the giant interface. Those can be tested separately from the code that uses the interface. Arguing against that is the idea that giant mocks can be shared among projects, thus saving the time spent creating the custom mocks required by my alternative. But I'm inclined to think it's a good practice to write an adapter layer anyway. Without one, it's painful to swap out components: uses of the old component's API are smeared throughout the system.
## Posted at 21:28 in category /coding
[permalink]
[top]
Fri, 26 Aug 2005A program should be able to answer the two questions parents so often ask young children:
Logging is an important tool toward that end. I think it's underused and too often misused. I wrote some patterns for using logging for PLoP 2000 (pdf). Pretty mediocre. Who's written what I should have? The TextTest people advocate using logging to capture the expected results of a business-facing test. I like when idea working on ugly legacy code.
## Posted at 08:57 in category /coding
[permalink]
[top]
Wed, 06 Jul 2005Breaking tests for understanding Roy Osherove has a post about breaking code to check test coverage. That reminded me of a trick I've used to counter a common fear: that changing something here will break something way over there.
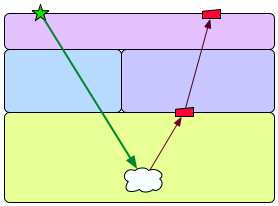
The picture is of a standard layered architecture. The green star at the top level is a desired user-visible change. Let's say that support for that change requires a change at the lower level - updating that cloud down at the bottom. But other code depends on that cloud. If the cloud changes, that other code might break. The thing I sometimes do is deliberately break the cloud, then run the tests for the topmost layer. Some of those tests will fail (as shown by the upper red polygon). That tells me which user-visible behaviors depend on the cloud. Now that I know what the cloud affects, I can think more effectively about how to change it. (This all assumes that the topmost tests are comprehensive enough.) I could run the tests at lower layers. For example, tests at the level of the lower red polygon enumerate for me how the lowest layer's interface depends on the cloud. But to be confident that I won't break something far away from the cloud, I have to know how upper layers depend on the lowest layer's to-be-changed behaviors. I'm hoping that running the upper layer tests is the easiest way to know that. But does this all stem from a sick need to get it right the first time? After all, I could just change the cloud to make the green star work, run all tests, then let any test failures tell me how to adjust the change. What I'm afraid of is that I'll have a lot of work to do and I won't be able to check in for ages because of all the failing tests. Why not just back the code out and start again, armed with knowledge from the real change rather than inference from a pretend one? Is that so bad? Maybe it's not so bad. Maybe it's an active good. It rubs my nose in the fact that the system is too hard to change. Maybe the tests take too long to run. Maybe there aren't enough lower-level tests. Maybe the system's structure obscures dependencies. Maybe I should fix the problems instead of inventing ways to step gingerly around them. I often tell clients something I got from The Machine that Changed the World: the Story of Lean Production. It's that a big original motivation behind Just In Time manufacturing was not to eliminate the undeniable cost of keeping stock on hand: it was to make the process fragile. If one step in the line is mismatched to another step, you either keep stock on hand to buffer the problem or you fix the problem. Before JIT, keeping stock was the easiest reaction. After JIT, you have no choice but to fix the underlying problem. So, by analogy, you should code like you know in your heart you should be able to. Those places you fall through the floor and plummet to your death are the places to improve. I guess not by you, in that case. By your heirs. |
|

 I started to proudly write up that trick. But the process of putting words
down on pixels makes me think I was all wrong and that it's a bad
idea. Read on to see how someone who's supposed to know what he's
talking about goes astray. (Or maybe it's a good idea after all.)
I started to proudly write up that trick. But the process of putting words
down on pixels makes me think I was all wrong and that it's a bad
idea. Read on to see how someone who's supposed to know what he's
talking about goes astray. (Or maybe it's a good idea after all.)




{kind=link}