Exploration Through Example
Example-driven development, Agile testing, context-driven testing, Agile programming, Ruby, and other things of interest to Brian Marick
| 191.8 | ⇒ | 167.2 | ⇒ | 186.2 | 183.6 | 184.0 | 183.2 | 184.6 |
Exploration Through ExampleExample-driven development, Agile testing, context-driven testing, Agile programming, Ruby, and other things of interest to Brian Marick
|
|
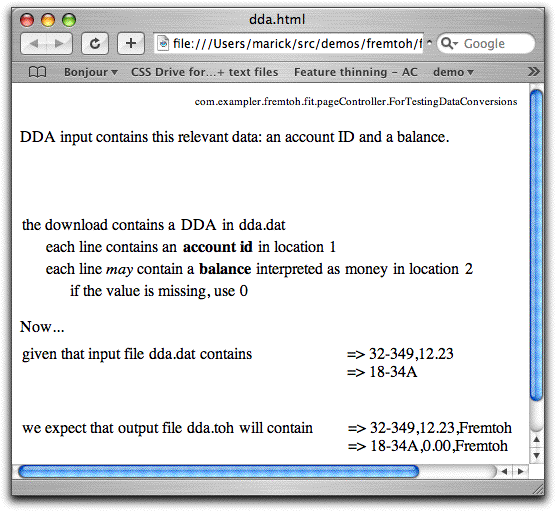
Thu, 22 Feb 2007Can business-facing tests make everyone happy? Fit has some problems:
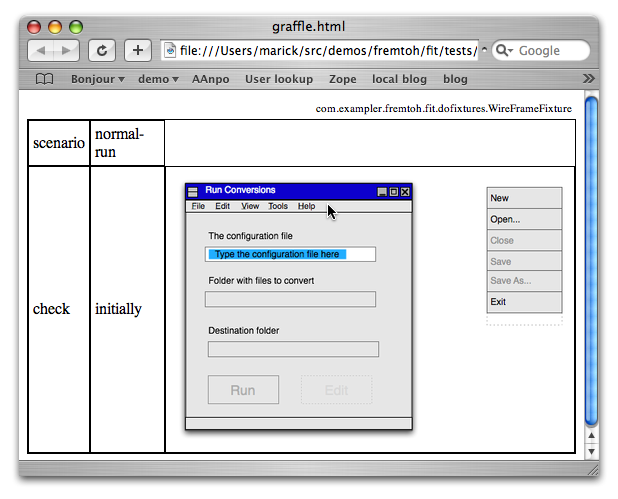
Maybe I'm groping toward a solution. Here is a Fit table that talks about a data conversion that's driven by a configuration file:
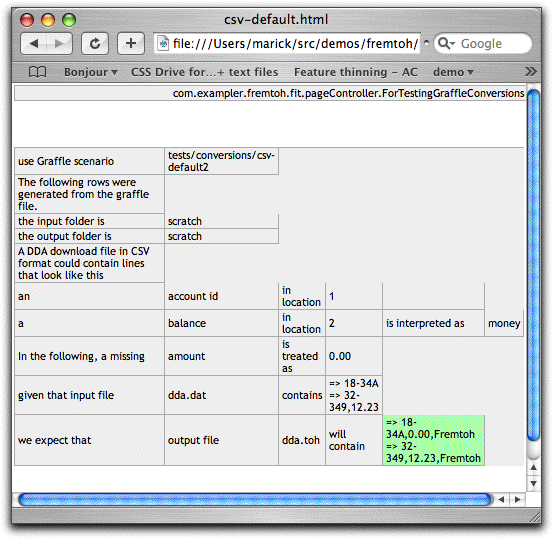
That looks reasonably attractive. You'd be appalled if you knew how much time I spent on it. Here is the same test in a different format:
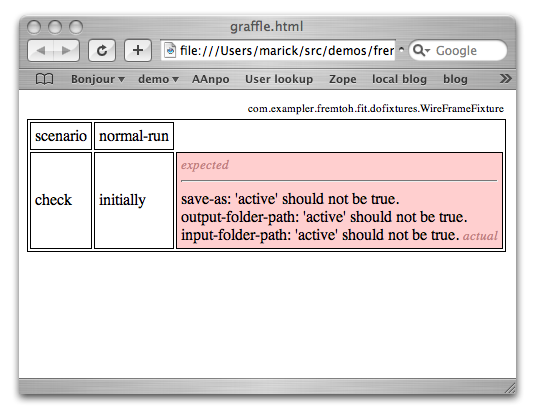
That's an OmniGraffle file. I think it required less fiddling to create. Updating seems to be easier. I think it would be more useful as documentation than the previous test would. What I've done behind the scenes is extend my existing Graffle parser to handle files like this. I still use the Fit engine behind the scenes, as you can see from the output:
Not so nice to read, but how many product directors really look at test output? Now the question is: how could this use JUnit as the test execution engine instead of Fit? Then the question after that is whether I could use a less obscure app than OmniGraffle to generate the tests. Anything that puts out XML should be roughly the same difficulty.
## Posted at 14:49 in category /fit
[permalink]
[top]
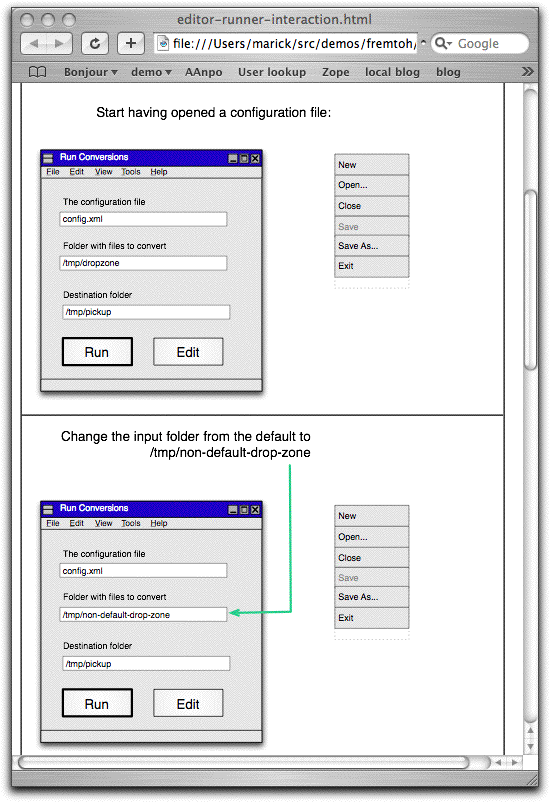
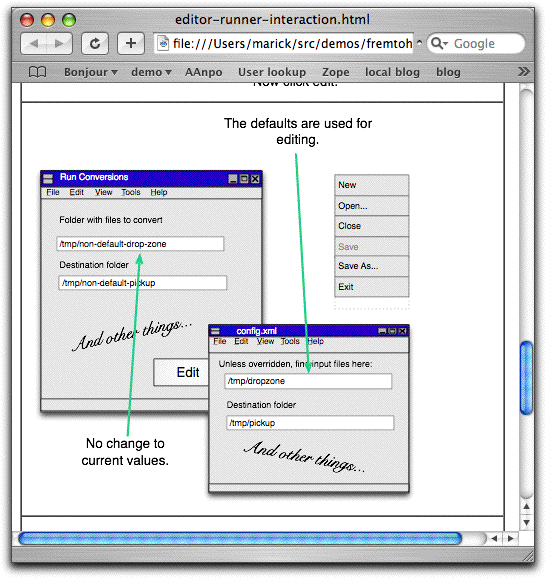
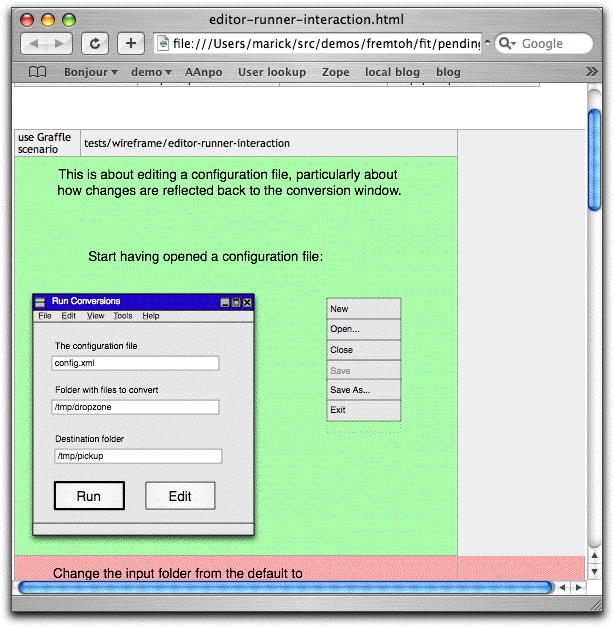
Thu, 18 Jan 2007A variation of wireframe testing Here's my last post on lively wireframe testing for a while. Again, the idea is to help with business-facing test-driven development in two ways. First: non-technical people like product directors often think about applications in terms of user interfaces. I think that's a problem, but trying to fix it right now just gets in the way of starting the project off smoothly. So this style of test is a compromise. Second: when using a highly-decoupled presenter-first style of development, you may need some way to remind yourself of all the pieces of user interface that should update in response to a user action. Looking at changes to pictures—wireframes—is a good way to do that. (Thus, some of these tests may be desirable even in an ideal project. What I'm objecting to in the previous paragraph is when all of the discussion about what the product should do is in terms of the user interface, not business rules, generalizations, abstractions, and exceptions.) What I show below is an improvement to the previous style. Suppose someone is preparing a sequence of wireframes to demonstrate a user workflow. She might naturally annotate the wireframe with comments about what the user will do next. Rather than redundantly enter those as Fit commands, I'll just use them directly. That requires less editing of HTML and more tweaking of OmniGraffle documents, which is a net win (HTML being a pain, even with Open Office). It also looks prettier. Aesthetics matters for acceptance. This improvement was not hard to implement, given FitLibrary and Omnigraffle's decent document layout. The code that sits behind the table is the same as normal DoFixture code. The Fit table for a wireframe workflow is nothing but a series of one-cell rows, each one corresponding to a step in the workflow or a page in the slide show. The contents of the input cell are ignored, so I have it show a snapshot of the corresponding Graffle page. (I made the tables by hand, but the images and HTML could be generated from the Graffle document by code—Applescript, Java, Ruby, whatever.) Here are the first two steps of such a workflow:
"Start having opened a configuration file" is, invisibly, an OmniGraffle Pro table. When the HTML cell is executed, all the Graffle tables that precede the graphics are interpreted as CamelCased method names and invoked. So the first table cell calls this:
... and then checks the state of the system-under-test against the (invisible) annotations on the page's wireframes.
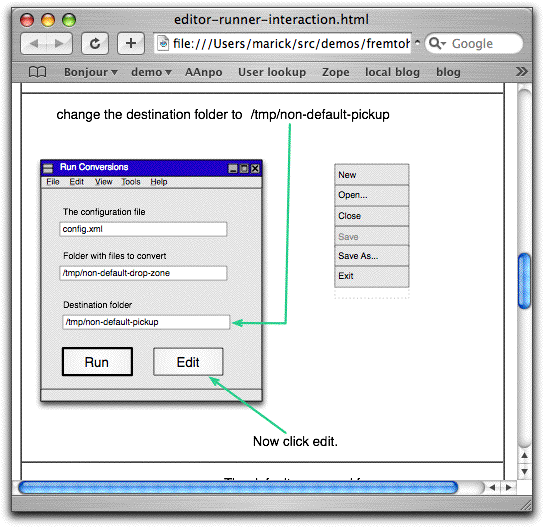
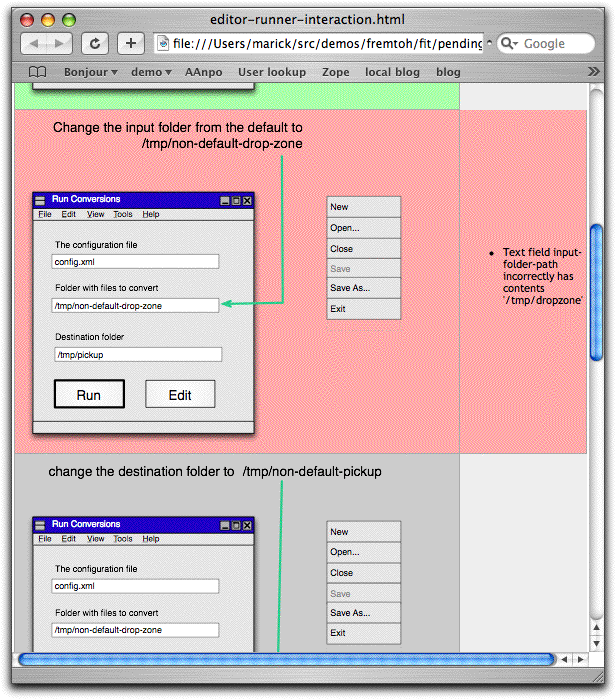
Then the next cell
calls It's often convenient to end a page with the command that takes you to the next one. That's what "Now click edit" does below.
So the sequence for the above cell is:
In order to reduce test fragility, I don't display controls irrelevant to the test, tagging them with "and other things...":
My hope is that, over time, people could get weaned away from realistic wireframes to absolutely minimalistic ones. Here's what a passing table cell looks like:
A not-yet-passing cell makes a list of what hasn't been done yet:
As shown above, once one cell fails, the rest of the cells are ignored (and colored grey). Otherwise, there would be annoying spurious failures. That fits well with a "make the next red green and don't worry about what happens after" style of development. That's as much work as I plan to do on new kinds of Fit fixturing for this app. Elisabeth Hendrickson has convinced me the next step should be to hook up an Ajaxy front end to the app and think about testing and test-driving that. Frankly, there's a lot more demand for figuring out the testing of Ajax apps than for exploration through example using Fit.
## Posted at 08:14 in category /fit
[permalink]
[top]
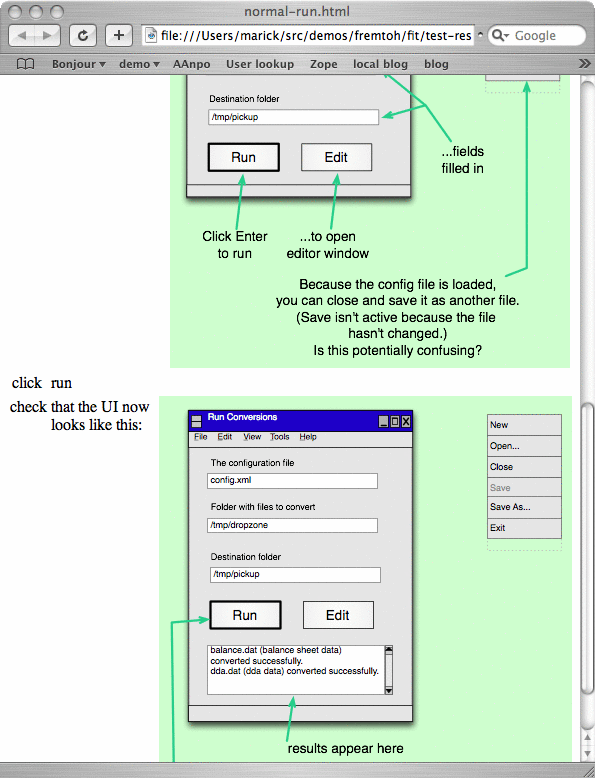
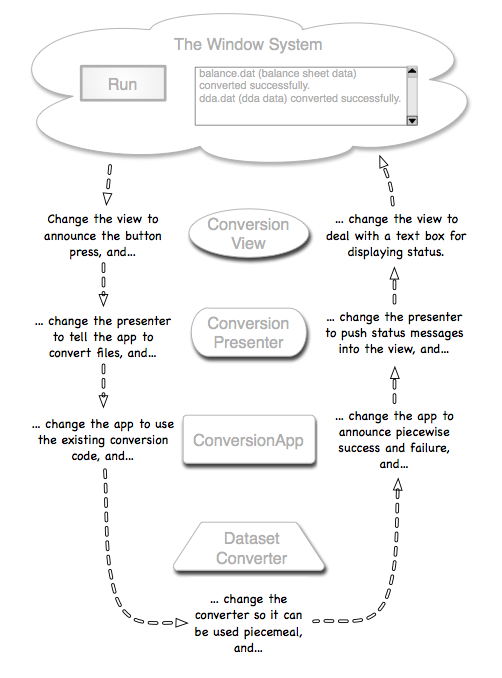
Thu, 11 Jan 2007Test-driving presenter-first design My notion of using lively wireframes as tests for a model/view/presenter style UI leads to finished tests like this:
The test is driven by an OmniGraffle Pro slide show annotated with test assertions. I used the test for test-driven development. For example, the last green box was red not long before I started this post. In order to make it green, I had to make the following changes, in roughly the order shown by the arrows:
That felt like straightforward, unexciting coding, which is what I want from TDD. The driving test is (arguably) business-facing. What of unit tests? In model/view/presenter, you're not expected to write unit tests for the thin view. The application (model) objects are unit tested like any normal object. The presenters are typically tested by putting mocks on either side, replacing the view and application. I didn't do that. Here's why.
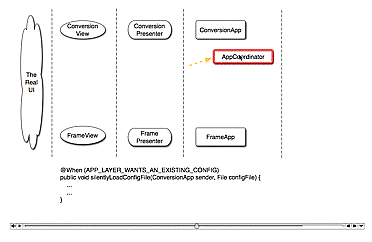
Consider the code that responds to the clicking of
the
Here's a typical presenter test, using mocks in place of
the
My first impression, looking at that, is that it's too much work for the code it tests. That's probably overstating it, since the test is stylized and straightforward to write. In fact, it's too straightforward: the test and the code are mechanical transformations of one another. Moreover, the transformation happens in one step (one test ⇒ one complete straight-line method) because all the "iffyness" of the code gets factored out into a profusion of different methods and the declarations of which announcements each responds to. (This is like the way switch statements can be factored into objects of different classes.) Because of all this, the unit test, even if written first, seems to lack the idea-generation virtues a unit test ought to have. You're not interspersing the coding of a method's internals with thinking about what visible behavior it should have. The behavior that matters is dispersed, and the method's internals are its behavior (since all it's for is telling other objects what to do). It's the wireframe test, not the unit test, that produces Aha! moments. It forces you to think about what counts: "when the user pokes at this button here, what should happen to all the bits of UI the user can see?" Before I thought of the idea of wireframe tests, I found it easy to overlook that a change in one window ought to produce changes in another. Nothing rubbed it in my face like the wireframes do. However, these wireframe tests look an awful lot like traditional GUI tests, and they may have their great weakness: many different tests share knowledge of the UI, so a product change that deliberately falsifies a bit of that knowledge will break many tests. I have some ideas about dealing with that problem in a way that GUI-driving tests cannot. Will they work out? Who knows? My development preference is probably unchanged: put off the UI (and especially UI tweaking) in favor of getting the business logic right. In the case of this program, I did a lot of work on the conversions before there was anything more than the crudest possible command-line UI. However, I've noticed and heard something in the past couple years: the trust of the business people is driven by how well the UI matches what they imagine of the finished product. Consider the novice product director—which is most of them, these days, at the start of projects. Thrust into a new situation, promised early and frequent delivery of business value, and largely unable to distinguish "the product" from "the UI", she demands—and gets—a UI first. I have faith that many product directors can, in time, come to see the product as being about business rules rather than about UI. But by the time, any damage due to working UI-first will have been done. Therefore, I think it prudent to find ways to make what the business wants (screen images) serve the team's need to have tests drive their code. That's why I'm hot on wireframes.
## Posted at 16:44 in category /fit
[permalink]
[top]
Fri, 05 Jan 2007Earlier, I promised some thoughts about how Fit and annotated wireframes can be used to test-drive user interfaces with a model-view-presenter architecture behind them—specifically, an architecture in the style advocated by the good folk at Atomic Object. In order to motivate those thoughts, I need you to understand Atomic Object's style and also get a glimpse of what lies beneath my application's UI. What lies beneath is one of those OO programs where no method does much of anything other than ask another object to do something. Those are hard to understand from a picture, so I made a movie. Click the image below if you want to see the first draft version. It requires QuickTime. The movie is 20Mbytes, but should start up promptly. It's 20 minutes long.
Let me know if you think the movie could be a helpful introduction to model-view-presenter. If so, I'll edit it to clean up transitions, dub over mistakes, tighten parts up, etc.
## Posted at 14:53 in category /fit
[permalink]
[top]
Tue, 19 Dec 2006Tests are better than requirements documents because they're more lively. Not only do they describe what the system is to do, they give strong hints about whether it does it. Requirements documents just sit there. The liveliness of tests makes up for the occasional awkwardness of their descriptions. (It's harder to write for two audiences—the human and the test harness—than it is to write for one.) In a series of talks I gave earlier this year, I described three types of business-facing tests: ones based on business logic, ones based on workflow, and ones based on wireframe mockups of a user interface. I talked about wireframes last, and what I had to say compared poorly to the previous two. Those tests had been simultaneously executable and OK-to-good at communicating. But, when it came to wireframes, the best I could do was draw one on a flipchart and say, "I wish I could lift that off and put it in the computer. The closest I can come is this..."
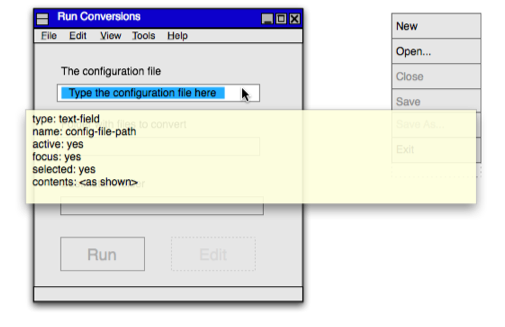
That's bad because we have two separate representations, each of which is lousy for one of the two audiences. I now think I have something better. Here's a wireframe:
It's a drawing created with OmniGraffle Pro (using a stencil from John Dial). That kind of wireframe is easy for a whole team to talk about, but it's too ambiguous for a testing tool. (How would it know whether a given rectangle is a text box, a text field, or the decoration at the bottom of the window?) Fortunately, Omnigraffle allows you to attach notes to graphics. The yellow tooltip-ish rectangle shows annotations to a text field that remove ambiguity. Here's a test that uses that wireframe:
The image is just there for human consumption. In real life, I'd want the human to work exclusively on the Graffle document and not think about PNG files at all. Instead, I'd have a script watch for changes to Graffle files and regenerate all the PNG images.
The actual test ignores the image. Instead, it parses the Graffle
file ("normal-run.graffle"), hooks the program up to a fake window
system that
records messages
like
The error messages could do a better job of pointing to the right control, and it's a shame that the image doesn't appear in the output. (Fit swallows it along with any other HTML tags in the test input. No doubt I could work around that.) However, this output is only for programmers already deep in the code. It doesn't have to be as friendly as output aimed at a wider audience. I still have two big open questions.
The next installment ties this into the Atomic Object style of model/view/controller, as described here (PDF) and in a forthcoming Better Software article. But first, I have to figure out how to parse canvases out of Graffle files. And there's that whole vacation thing.
## Posted at 21:50 in category /fit
[permalink]
[top]
Thu, 30 Nov 2006I've started using OpenOffice (in its Mac-ified NeoOffice form) for writing Fit tables. It's working considerably better than Word. Not only does it produce decent HTML (valuable when you're trying to figure out exactly what's going on), it does a better job of producing an HTML file that looks similar to the original WYSIWYG editor view, both when displayed through a browser and when read back into the editor. I should note that I'm still using Word X for the Mac, so others might have better luck with Word than I've had. But if Word isn't working well for you, check out OpenOffice.
## Posted at 06:47 in category /fit
[permalink]
[top]
Tue, 17 Oct 2006A fixture for Boolean-valued business logic I've implemented the fixture described earlier. It takes a table in a particular format, generates a new ColumnFixture table, and causes that table to be executed. You can see the Fit output a programmer works with here. The source and jar file are at http://www.exampler.com/testing-com/tools/fitlibrary-extensions-0.1.zip. The README.txt file will tell you about examples. I believe it works correctly, and I put it to the test at a client's on Monday. Nevertheless, it is an early version: I made no attempt to handle malformed input gracefully. I haven't made it work with DoFixture yet. I need to clean up the source directory structure. (JUnit tests are intermingled with source files.) I realize that the fixture knows almost enough to generate much of the ColumnFixture code for you, so I'm going to add that. The version in the zip file was compiled under Java 1.4, though it is likely to compile under earlier versions.
## Posted at 16:57 in category /fit
[permalink]
[top]
Wed, 27 Sep 2006My examples below use a simple rule for deciding what values of a boolean expression to test. I should probably describe it and justify it.
Given an expression with all
So the table for
The case for
The reasoning behind these rules is based on mutation testing, the name for a long thread of academic research on testing. The way I state it (which is different in an unimportant way from how it's usually put) is that mutation testing involves assuming that the code is incorrect in some definable way, then asking for a test suite that can distinguish the incorrect code you have from the correct code you should have. Now, for any given program, there are an infinite number of variants, so mutation testing depends on picking a definition-of-incorrectness that (a) lets you generate a reasonably small set of alternatives, but (b) gives you confidence that you've caught all the plausible errors. The usual approach is to assume one-token errors.
For example, suppose you are given
One-token errors aren't the only ones you could make. For example,
you might completely forget that
Suppose you have the original Trying all the possible combinations of variable values will either find a one-token error or kill all the mutants. But you never have to try all of them. There will be some test inputs that don't add anything: any mutant they kill will be killed by some other test input. So you can construct a minimal set for any given expression.
If you look at the table below, you can see that the rule
for
Remember all this assumes that tests powerful enough to catch
one-token errors will catch more complicated (but still plausible)
errors. A way to convince yourself is to try and find a variant
of
These rules are easy to memorize. The cases for expressions that
mix
When using the style I described earlier, I don't think you need
multi, because I'm tentatively advocating always breaking tables that
combine
1 I can't remember if the transformations I used when
working all this out included substituting one variable for another
(like 2 I'm leaving what it means to "run a program" vague. That gets to the difference of whether the mutation is "weak" or "strong". See this post by Ivan Moore. I didn't find much in the online literature about mutation testing; if you want to know more, you'll have to go to the library. There are some starting references at the end of this paper (PDF).
## Posted at 08:36 in category /fit
[permalink]
[top]
Sun, 24 Sep 2006Describing yes/no choices in Fit Using Fit to describe boolean (yes/no) decisions can be much clearer if you just insist that all decisions be expressed in multiple, uniform, simple tables. No boolean expressions in the code may mix Suppose you're given a jumble of three packs of cards. You are to pick out every red numbered card that's a prime, not rumpled, and is from either the Bicycle pack or the Bingo pack (but not from the Zed pack). Here is a way you could write a test for that using CalculateFixture:
I bet you skimmed over that, read at most a few lines. The problem is that the detail needed to be an executable test fights with the need to show what's important. This is better:
That highlights what's important: any card must successfully pass a series of checks before it is accepted. This test better matches what you'd do by hand. Suppose the cards were face down. I'd probably first check if it were rumpled. If so, I'd toss it out. Then I'd probably check the back of the card to see if it had one of the right logos, flip it over, check if it's black or a face card (two easy, fast checks), then more laboriously check if it matches one of the prime numbers between 2 and 10 (discarding Aces at that point). The code would be slightly different because it has different perceptual apparatus, but still pretty much the same:
It does bug me that the table looks so much more complex than the code it describes. It still contains a lot of words that don't matter to either the programmer or someone trying to understand what the program is to do. How about this?
From this, the Fit fixture could generate a complete table of all the given possibilities, run that, and report on it. (Side note: why did I pick Queen as a counterexample instead of Jack or King? Because if the program is storing all cards by number, the Queen will be card 11. Since I'm not going to show all non-primes—believing that more trouble than it's worth—I should pick the best non-primes.) The same sort of table could be created for cases where any one of a list of conditions must be true. Now, many conditions are more complicated than all of or none of or any one of. However, all conditions can be converted into one of those forms. Here's an example. Suppose you're allowed to pay a bill from an account if it has enough money and either the account or the "account view" allows outbound transfers. That would be code like this:
However, that could also be written like this:
I claim that code is just as good or even better. It's better
because there's less of a chance of a typo leading to a bug
(writing The corresponding tables would be like this:
In this particular case, I left off the Example and Counterexample columns because they're obvious. I'd expect the fixture to fill them in form me. I didn't include a table about the balance being correct because I wouldn't think the programmers would need it, nor would others need it to believe the programmers understand it. One thing that worries me about this is that the table doesn't rub your nose in combinations. Such a table is more likely to force you to discover business rules you'd forgotten about, that you'd never known about, or that no one ever knew about. (Well, it does that for a while - until the tedium makes your mind glaze over.) In a way, this fixture makes things too easy. On the other hand, there's something to be said for protecting later readers from the process through which you convinced yourself you understood the problem. I'm tempted to launch into implementing this, but I have other things to work on first.
## Posted at 11:49 in category /fit
[permalink]
[top]
Wed, 02 Nov 2005Here are three links I plan to point clients at:
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||